本文共 2076 字,大约阅读时间需要 6 分钟。
文章目录
官网:
官网学习资料:ES简介
Elasticsearch 是一个开源的搜索引擎,建立在全文搜索引擎库 Apache Lucene 基础之上。
用 Java 编写的,它的内部使用 Lucene 做索引与搜索,但是它的目的是使全文检索变得简单, 通过隐藏 Lucene 的复杂性,取而代之的提供一套简单一致的 RESTful API。
Elasticsearch 不仅仅只是一个全文搜索引擎。 它可以被下面这样准确的形容:
- 一个分布式的实时文档存储,每个字段可以被索引与搜索(可以当做数据库使用)
- 一个分布式实时分析搜索引擎
- 能胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据
备注:选型上,一般ES用的会比solr多,solr相对比较复杂,太多配置,而ES会相对简单很多
ES流行度
DB-Engines(一家收集和统计数据库管理系统信息的机构,网址: )上的搜索引擎排名:
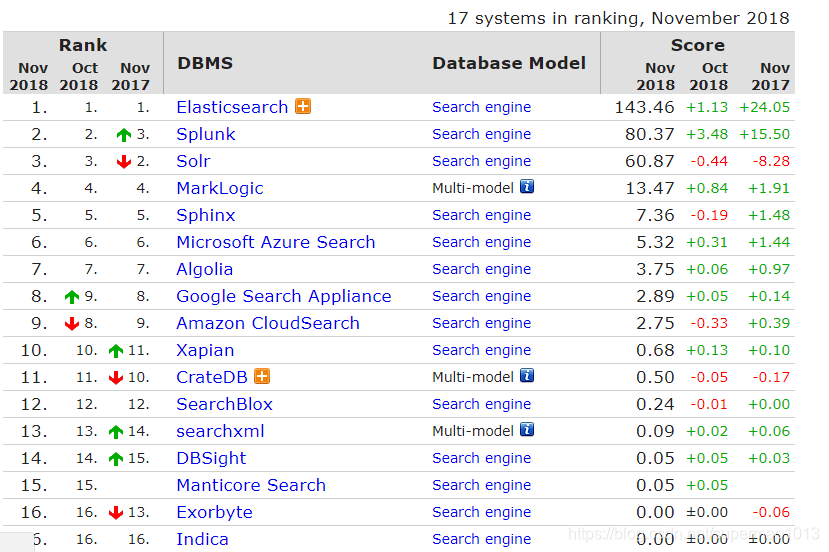 除此之外,用作数据库的排名也不错:
除此之外,用作数据库的排名也不错: 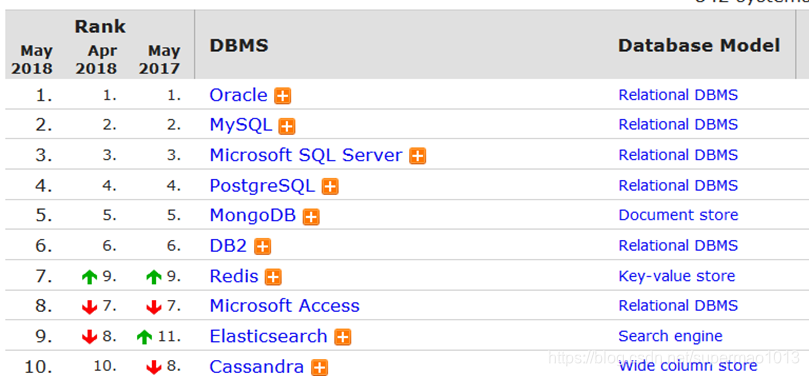
ES特性
速度快、易扩展、弹性、灵活、操作简单、多语言客户端、X-Pack、hadoop/spark强强联手、开箱即用。
- 分布式:横向扩展非常灵活
- 全文检索:基于lucene的强大的全文检索能力
- 近实时搜索和分析:数据进入ES,可达到近实时搜索,还可进行聚合分析
- 高可用:容错机制,自动发现新的或失败的节点,重组和重新平衡数据
- 模式自由:ES的动态mapping机制可以自动检测数据的结构和类型,创建索引并使数据可搜索。
- RESTful API:JSON + HTTP
ES应用场景
- 站内搜索
- NoSQL数据库
- 日志分析
- 数据指标分析
ES大致架构
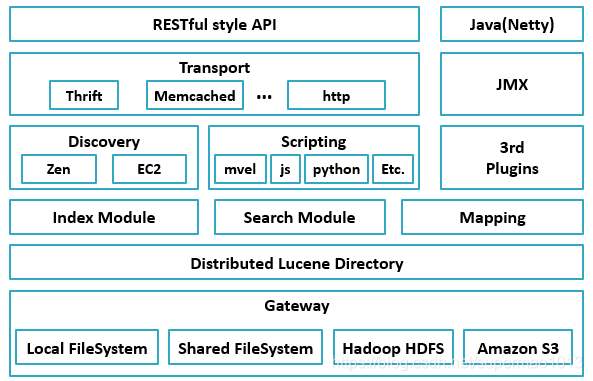
- Gateway是ES用来存储索引的文件系统,支持多种类型
- Gateway的上层是一个分布式的lucene框架
- Lucene之上是ES的模块,包括:索引模块、搜索模块、映射解析模块等
- ES模块之上是 Discovery、Scripting和第三方插件。Discovery是ES的节点发现模块,不同机器上的ES节点要组成集群需要进行消息通信,集群内部需要选举master节点,这些工作都是由Discovery模块完成。支持多种发现机制,如 Zen 、EC2、gce、Azure。Scripting用来支持在查询语句中插入javascript、python等脚本语言,scripting模块负责解析这些脚本,使用脚本语句性能稍低。ES也支持多种第三方插件,比如加入中文分词器
- 再上层是ES的传输模块和JMX。传输模块支持多种传输协议,如 Thrift、memecached、http,默认使用http。JMX是java的管理框架,用来管理ES应用
- 最上层是ES提供给用户的接口,可以通过RESTful接口和ES集群进行交互
ES核心概念
-
Near Realtime(NRT)近实时:数据提交索引后,立马就可以搜索到
-
Cluster集群:一个集群由一个唯一的名字标识,默认为“elasticsearch”。集群名称非常重要,具有相同集群名的节点才会组成一个集群,集群名称可以在配置文件中指定
-
Node节点:存储集群的数据,参与集群的索引和搜索功能。像集群有名字,节点也有自己的名称,默认在启动时会以一个随机的UUID的前七个字符作为节点的名字,你可以为其指定任意的名字。通过集群名在网络中发现同伴组成集群。一个节点也可是集群。
-
Index索引: 一个索引是一个文档的集合(等同于solr中的集合)。每个索引有唯一的名字,通过这个名字来操作它。一个集群中可以有任意多个索引。
-
Type类型:指在一个索引中,可以索引不同类型的文档,如用户数据、博客数据。从6.0.0 版本起已废弃,一个索引中只存放一类数据。
-
Document文档:被索引的一条数据,索引的基本信息单元,以JSON格式来表示。
-
Shard分片:在创建一个索引时可以指定分成多少个分片来存储。每个分片本身也是一个功能完善且独立的“索引”,可以被放置在集群的任意节点上。分片数在创建索引时指定,创建后不可改了,而备份数可以随时改。分片的好处:
- 允许我们水平切分/扩展容量
- 可在多个分片上进行分布式的、并行的操作,提高系统的性能和吞吐量。
-
Replication备份: 一个分片可以有多个备份(副本)。备份的好处:
- 高可用
- 扩展搜索的并发能力、吞吐量。搜索可以在所有的副本上并行运行
ES对比RDBMS
| | |
|---|---|
| 索引(index)(也可以理解为表) | 数据库(database) |
| 类型(type)(6.0.0废弃) | 表(table) |
| 文档(document) | 行(row) |
| 字段(field) | 列(column) |
| 映射(mapping) | 表结构(schema) |
| 反向索引 | 索引 |
| 查询DSL | SQL |
| GET http://… | SELECT * FROM table |
| PUT http://… | UPDATE table SET |
| DELETE http://… | DELETE |
转载地址:http://agsxi.baihongyu.com/